Glue Catalog
Glue Catalog - It acts as an index to the location, schema, and runtime metrics of your data sources. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. The data catalog contains table definitions, job definitions, schemas, and other control information to help you manage your aws glue environment. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. For more information, see aws glue data catalog. You can create a single view object with a different sql version for each engine you want to query, such as amazon athena, amazon redshift, and spark sql on amazon emr. Aws glue has released a new feature, sql views, which allows you to manage a single view object in the data catalog that can be queried from sql engines. To build a foundation for discovery. It highlights the role of glue crawlers, querying. It highlights the role of glue crawlers, querying. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3. Streamline discovery, management, and analysis with amazon datazone and aws glue data catalog. The aws glue data catalog is your persistent metadata store for all your data assets, regardless of where they are located. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. It does not store the actual data, it only keeps track of where the data is, what it looks like, and how it is. It is a managed service that you can use to store, annotate, and share metadata in the aws cloud. The aws glue data catalog is your persistent technical metadata store. It provides a unified interface to store and query information about data formats, schemas, and sources. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. It highlights the role of glue crawlers, querying. It does not store the actual data, it only keeps track of where the data is, what it looks like, and how it is. The data catalog contains table definitions, job definitions, schemas, and other control information to help you manage your aws glue environment. It acts as an index to the. It highlights the role of glue crawlers, querying. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. You can visually create, run, and monitor extract, transform, and load (etl) pipelines to load data into your data lakes. The data catalog is part of aws glue,. Streamline discovery, management, and analysis with amazon datazone and aws glue data catalog. Key benefits of using aws glue catalog include: The aws glue data catalog is your persistent metadata store for all your data assets, regardless of where they are located. It is a managed service that you can use to store, annotate, and share metadata in the aws. Think of aws glue catalog as a table of contents for your data stored in s3. Unified discovery and analysis using amazon athena, amazon redshift, and more. To build a foundation for discovery. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. It provides a. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. For more information, see aws glue data catalog. Key benefits of using aws glue catalog include: Think of aws glue catalog as a table of contents for your data stored in s3. It provides a unified interface to store and query. It does not store the actual data, it only keeps track of where the data is, what it looks like, and how it is. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3. With aws glue, you can discover and connect to more than 70 diverse. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3. It acts as an index to the location, schema, and runtime metrics of your data sources. To build a foundation for discovery. It highlights the role of glue crawlers, querying. Unified discovery and analysis using amazon athena,. It is a managed service that you can use to store, annotate, and share metadata in the aws cloud. The data catalog contains table definitions, job definitions, schemas, and other control information to help you manage your aws glue environment. It acts as an index to the location, schema, and runtime metrics of your data sources. For more information, see. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. The aws glue data catalog is your persistent metadata store for all your data assets, regardless of where they are located. The aws glue data catalog is your persistent technical metadata store. The aws glue data catalog is a centralized repository. The aws glue data catalog is your persistent metadata store for all your data assets, regardless of where they are located. It highlights the role of glue crawlers, querying. It acts as an index to the location, schema, and runtime metrics of your data sources. Unified discovery and analysis using amazon athena, amazon redshift, and more. It is a managed. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. It highlights the role of glue crawlers, querying. The aws glue data catalog is your persistent metadata store for all your data assets, regardless of where they are located. The data catalog contains table definitions, job definitions, schemas, and other control information to help you manage your aws glue environment. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Aws glue has released a new feature, sql views, which allows you to manage a single view object in the data catalog that can be queried from sql engines. It provides a unified interface to store and query information about data formats, schemas, and sources. It is a managed service that you can use to store, annotate, and share metadata in the aws cloud. Unified discovery and analysis using amazon athena, amazon redshift, and more. Key benefits of using aws glue catalog include: For more information, see aws glue data catalog. It acts as an index to the location, schema, and runtime metrics of your data sources. The aws glue data catalog is your persistent technical metadata store. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3.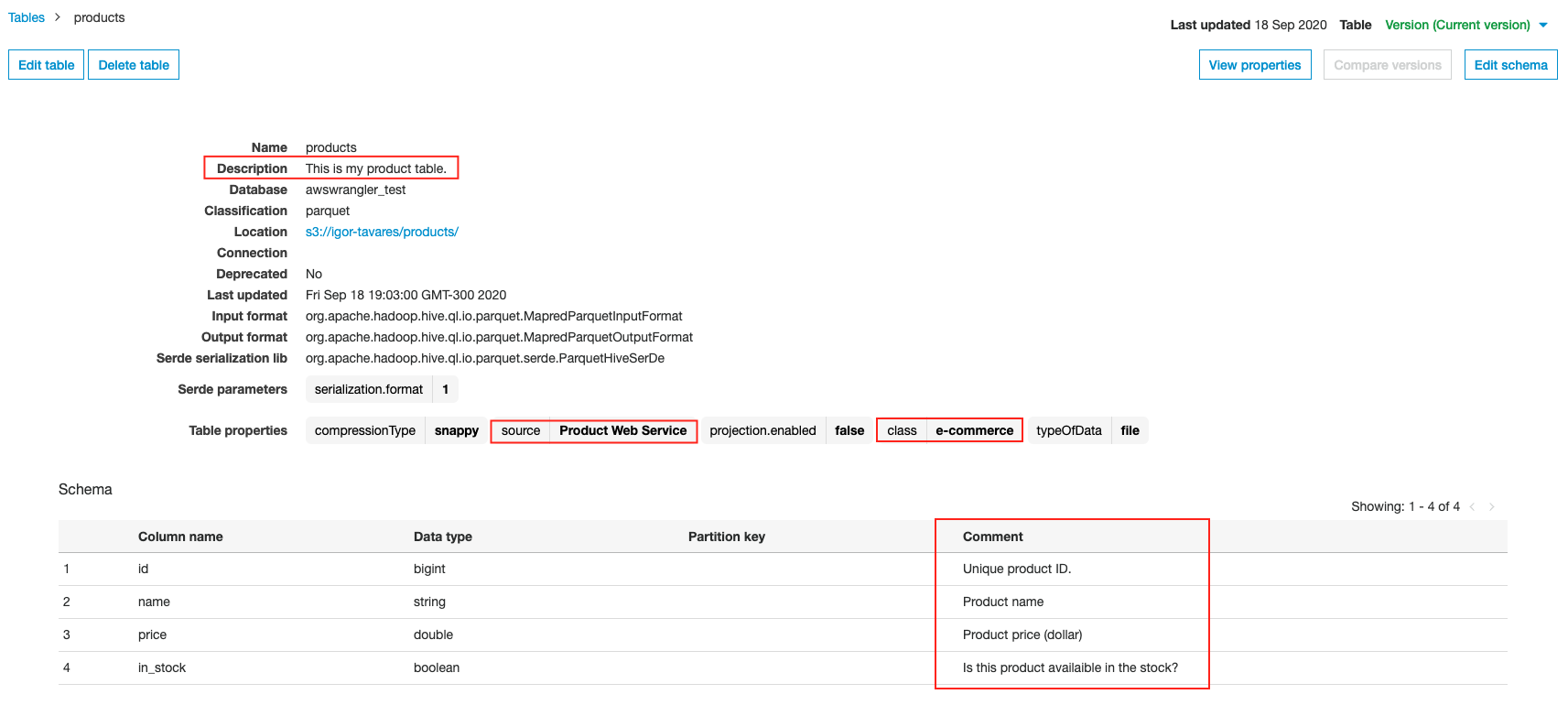
5 Glue Catalog — AWS SDK for pandas 3.11.0 documentation

Access Amazon S3 data managed by AWS Glue Data Catalog from Amazon

AWS Glue 101 Lesson 1 The Glue Data Catalog And Crawlers YouTube
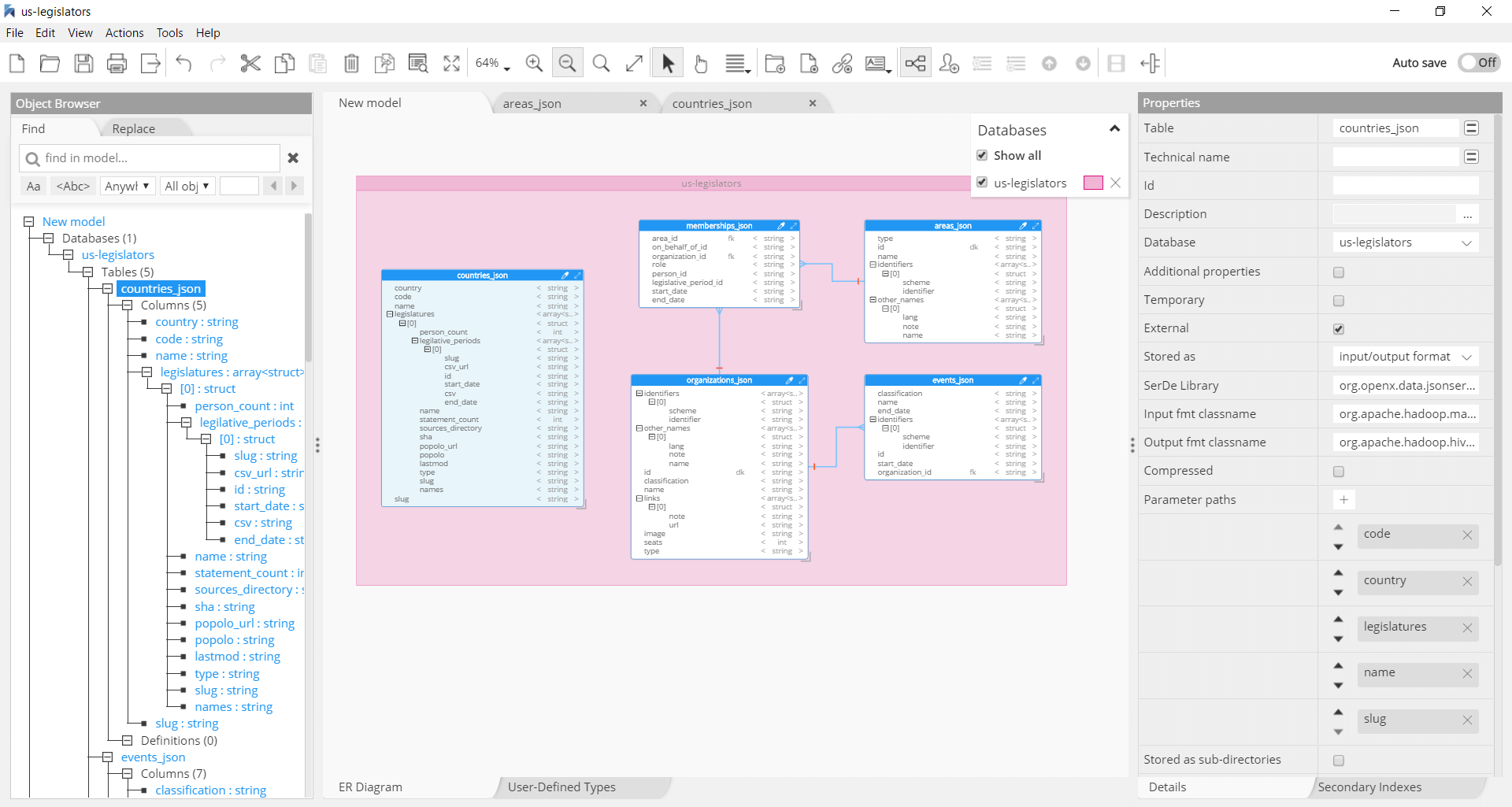
Glue Data Catalog
Load data from AWS S3 to AWS RDS SQL Server databases using AWS Glue

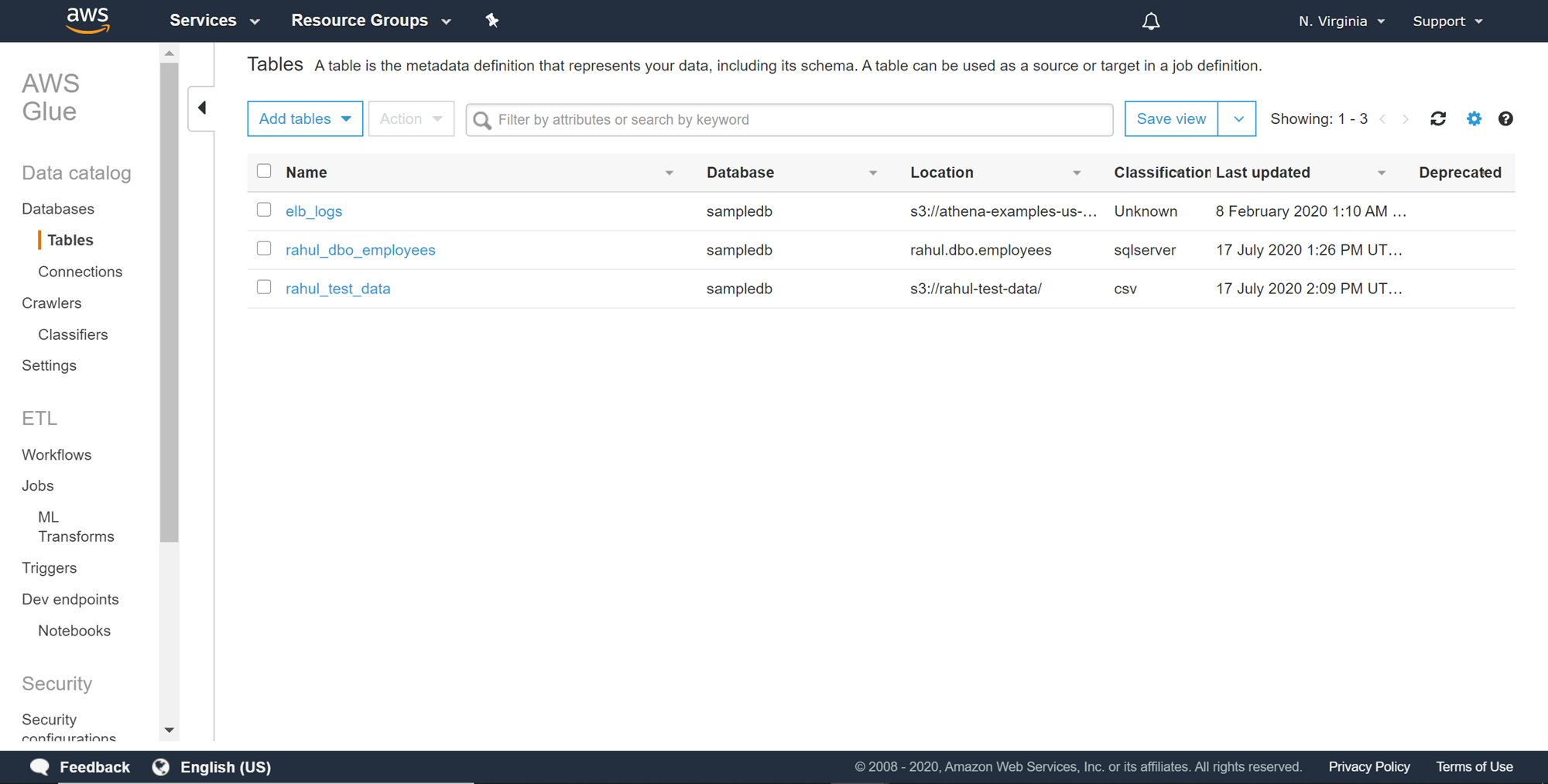
Populating the AWS Glue Data Catalog AWS Glue

Build operational metrics for your enterprise AWS Glue Data Catalog at

AWS Glue Data Catalog as the centralized metastore for Athena & PySpark

Simplify data discovery for business users by adding data descriptions

Build operational metrics for your enterprise AWS Glue Data Catalog at
To Build A Foundation For Discovery.
You Can Create A Single View Object With A Different Sql Version For Each Engine You Want To Query, Such As Amazon Athena, Amazon Redshift, And Spark Sql On Amazon Emr.
Streamline Discovery, Management, And Analysis With Amazon Datazone And Aws Glue Data Catalog.
Speak The Language Of Business By Adding Context And Meaning To Your Data Assets.
Related Post: